Automation and Agents: How to Overcome Your Data Preparation Challenges in LLM Fine-Tuning

Key takeaways
- Enterprises lose an average of $406M per year due to low-quality data and underperforming models.
- Data preparation is a time and labor-intensive process that requires gathering, structuring, and labeling data to train and fine-tune a base model.
- Creating high-quality training data is essential for successful model development, but overcoming inaccuracies, biases, and inconsistencies is a significant challenge for enterprises.
- Development teams are turning to automation to overcome data preparation challenges. These automated tools leverage ML technologies to speed up processes and improve the overall quality of data.
- Agentic workflows present new opportunities for development teams to accelerate development cycles, enhance data quality, and improve model performance.
- Agentic data transformation in the SeekrFlow™ AI platform autonomously creates high-quality training data for fine-tuning, reducing data preparation time from months to days and significantly decreasing AI production costs.
Data preparation: the biggest challenge in LLM fine-tuning
Data preparation is the first and most important step in the LLM fine-tuning process—it also presents big barriers for data and development teams to overcome. The quality of training data directly impacts the fine-tuned model’s performance, accuracy, and time-to-market.
Enterprises lose an average of 6% of global annual revenue, or $406M, due to data inefficiencies and inaccuracies. This is because the data preparation process is extremely difficult, requiring hundreds of hours, and sometimes hundreds of people, to sift through data scripts and ensure training data is well-structured, logical, and cleansed of errors and biases.
The traditional data preparation process for fine-tuning:
In the traditional model training world, data scientists need to find, structure, annotate, and label data before they can begin fine-tuning an LLM.
Gathering data
This entails crawling the internet to compile data or sourcing data from a third-party content aggregator.
Structuring data
The gathered data is typically raw and unorganized. It needs to be formatted in a way that the model can understand. Often done manually, this is a labor- and cost-intensive process. Creating scripts can help teams expedite the process, but are still slow and expensive in comparison to more automated solutions.
Annotating and labeling data
This step in the process varies depending on whether you perform supervised or unsupervised learning:
- Supervised learning requires labeled data to provide the model with a map from inputs to outputs. This process creates a predictive model that can make autonomous decisions based on a set of logic. It is often used in applications like predictive analytics, image recognition, and classification.
- Unsupervised learning provides the model with unlabeled data and employs it with detecting patterns, structures, and relationships within the data. Not all use cases can utilize unsupervised learning.
Combating biases and errors
Because of the number of human annotators involved in the process—each with their own personal biases—teams spend significant time and resources inspecting data to overcome inconsistencies in structuring and labeling.
Repeating the cycle
In fine-tuning, it’s uncommon for the first round of data preparation to produce accurate and desired model outcomes. Development teams often need to repeat the data preparation process several times to identify and correct inaccuracies, biases, and contextual errors affecting model performance.
Applying automation to data preparation
Development teams are turning to automation to help them overcome data preparation challenges. These automated tools utilize ML technologies to speed up processes and improve the overall quality of training data.
There are several ways automation tools can support the data process, including:
- Data formatting and clustering
- Missing data detection
- Data consolidation
- Anomaly and error detection to help mitigate biases
- Synthetic data generation
Automation helps reduce the number of human resources required for data preparation, thus improving speed, efficiency, and accuracy in model training.
Transform your data into industry-specific solutions
Learn MoreUsing AI agents to automate data preparation
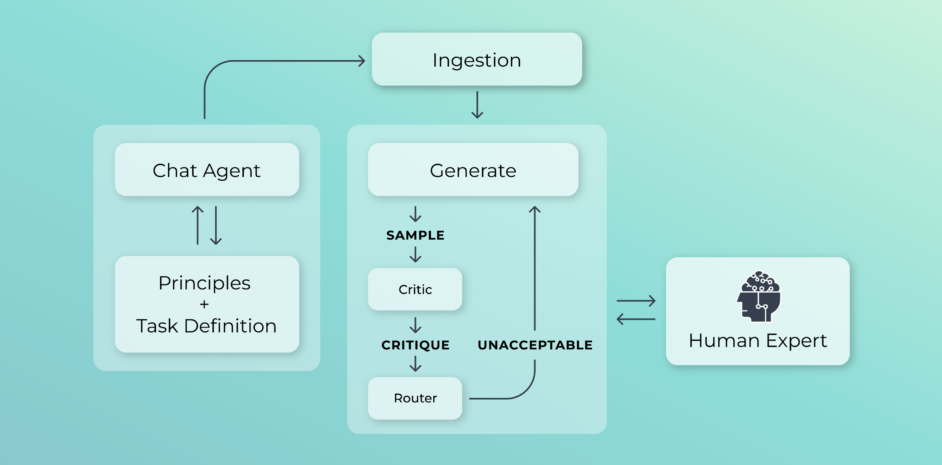
Seekr’s Principle Alignment feature offers a unique solution to automate data preparation. In this process, development teams can skip the gathering, structuring, and labeling process and instead utilize an agentic workflow to automatically generate high-quality training data for LLM fine-tuning.
Here’s how it works:
Define principles
The developer provides the high-level principles or specific policy documents that they expect the model to understand and adhere to. These principles could range from industry compliance regulations like FDA Title 21, a company’s return policy, brand safety guidelines, or general principles like the definition of hate speech.
Data ingestion
The AI agent ingests these principles and creates a hierarchy of information, organizing it into structured data that an LLM can understand. In addition to the structured principles, the agent has access to external tools such as web search APIs, knowledge graphs, calculators, code interpreters, and more.
Self-critiquing
The agent begins asking the document questions, predicting questions a human would traditionally ask around the specific topic and creating question/answer pairs. This process allows the agent to research, generate, critique, and refine the understanding of the principles.
Human-in-the-loop
Throughout the process, subject matter experts can iteratively provide feedback on the model’s understanding of the principles to refine the generation of synthetic data and maximize accuracy.
Synthetic data creation
At the end of the process, the agent provides high-quality, principle-aligned data ready for model fine-tuning.
Benefits of Principle Alignment
Consistent, quality datasets
Reducing the number of human annotators in data preparation reduces the number of inconsistencies and biases in training data. An agentic workflow can produce consistent datasets without the presence of human biases.
Reducing expenses pre and post-deployment
We estimate that SeekrFlow reduces the cost of generating training data by an average of 9x compared to traditional data preparation methods.
Producing one training data example costs $0.10-$0.50 using Principle Alignment compared to $2-$3 per example using manual annotation. These numbers don’t count the additional overhead costs of data gathering, which Principle Alignment further reduces.

Principle Alignment helps enterprises create a fine-tuned specialist model that deeply understands their defined documentation and principles. By infusing domain knowledge into the model during training, enterprises can reduce their reliance on retrieval-augmented generation (RAG) in certain use cases, thereby lowering the overhead costs of AI in production.
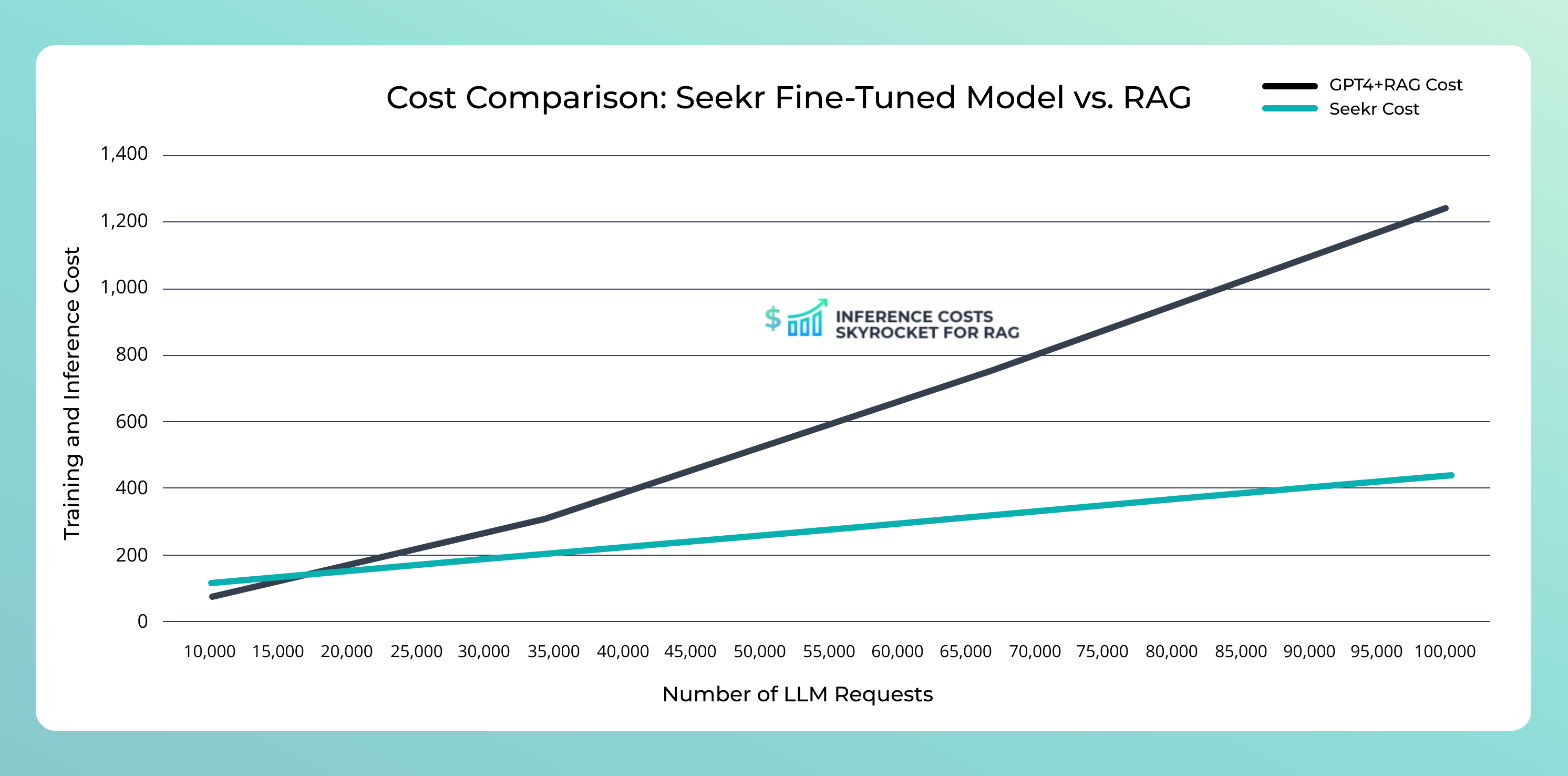
In the above example we compared the training and inference costs of a Seekr fine-tuned LLM vs. a GPT4-o model that has been paired with RAG—the Y axis represents cost, the X axis represents LLM requests.
SeekrFlow costs more initially because the model is being fine-tuned to learn domain-specific information. As the number of requests increases on the X axis, Seekr’s inference cost rises at a much lower rate compared to the GPT-RAG combo, where costs skyrocket due to the need to look up data with each request, dramatically increasing token usage and costs.
To put this example in a business context: if you have a chatbot with a million daily users who average five prompts, you could pay an extra $16,500 a day, or $6 million a year.
Identifying use cases for Principle Alignment
Low amount of training data
Principle Alignment is especially useful in use cases where you don’t have a sufficiently large training dataset. Your pre-defined principles serve as the guidelines or constraints within which the model operates, ensuring it aligns with specific behavioral requirements, standards, or ethical considerations.
Industry regulations
This process can be particularly useful for enterprise applications required to follow strict industry regulations. For example, the healthcare industry may require adherence to HIPAA guidelines, while the finance industry may enforce compliance with FINRA regulations.
To learn more about generating industry-specific training data, see our docs on aligning an LLM to FDA regulations or airline policies with SeekrFlow’s Principle Alignment feature.
Takeaways
Automation is transforming the landscape of data preparation, addressing the labor-intensive and time-consuming nature of traditional methods. Agentic workflows streamline the process of gathering, structuring, and labeling data. This speeds up data preparation but also enhances the quality and consistency of training data, overcoming challenges of biases and inaccuracies.
Leveraging high-quality, principle-aligned synthetic data helps development teams ensure their models meet specific regulatory and ethical standards. As automation continues to evolve, more organizations will recognize the need to adopt these technologies to drive better outcomes from their AI investments.