Key takeaways
- Data governance is central to your AI success. Without a framework for understanding and managing your data, you run the risk of improperly using it in your training efforts—leading to potential security breaches, non-compliance, and irresponsible AI outcomes.
- In the beginning, think small. Exploring AI through a single use case that you’re confident you have data to support can help you think through your data governance approach.
- To start sorting, just grab a few buckets. Kickstart your framework by creating a high-level cataloging structure, then add detail as you go—including as you explore that first pilot use case.
- The SeekrFlow™ AI platform can help you solve data limitations without risking governance problems. Our AI-Ready Data Engine quickly builds more robust datasets, even if your good-to-use data is limited.
Data governance is essential for any enterprise looking to succeed with AI. But implementing it, particularly when you have decades of historical data to account for, can be a challenging and time-consuming exercise. For many, getting started at all is a tough task.
Still, the reality is that AI is an urgent business priority for most enterprises. AI leaders need to balance speed with careful governance practices. To help you thread that needle, this article shares valuable tips, insights, and best practices so you can embrace AI with confidence in your data use. Let’s dive in.
What is data governance?
It’s important to first understand the overall goal of data governance strategies, which can involve various frameworks, policies, and processes that help organizations ensure their data is properly managed and used. Without a data governance framework, organizations risk using data they don’t own or unknowingly employing sensitive information to fuel their AI solutions, which can lead to legal complications down the road.
Overall, data governance looks to ensure that:
- Data is properly organized and categorized based on your organization’s needs
- Data is up to quality standards and has been checked for viability, lineage, and cleanliness
- Data is stored, managed, and used in compliance with regulatory standards
One of the primary areas of concern for data governance in AI is model training. Here, your strategy should draw clear boundaries around your various data sources and the role they can play. You’ll want to have some idea of this before you get started in earnest.
Tip 1: Start your AI exploration with a single use case
As your business gets deeper into AI, it’s likely you’ll end up with an entire fleet of LLMs, all tuned to specific purposes. But in the beginning phases of your AI development practice, it’s best to start with a single use case—for both the efficiency of development and for controlling the data used for training.
Exploring a single use case allows you to understand your data needs. It can also clarify the different categories of data you have access to or the different types of data you plan to collect in the future. As you assess data for your first target use case, you’ll likely cast a wide net. As you sort through each potential source, it’s important to thoroughly assess quality and ensure usability. This includes involving domain experts and legal counsel to verify the data’s suitability and navigate compliance requirements. Legal counsel can also play a critical role in reviewing the outputs of your initial AI application, ensuring they align with governance standards and functional goals.
Starting small also allows you to avoid accidentally amplifying minor mistakes across a vast number of different projects. Select a use case where you’re confident the data can support your goals—whether it’s well-documented internal processes or reams of high-quality customer data. This focused approach not only defines your data governance strategy but also fosters collaboration between stakeholders, such as domain experts and legal advisors, ensuring both data quality and functional validation.
Tip 2: Establish a simple catalog system for your data
For organizations with substantial legacy data, it’s critical to determine what data can and cannot be used for AI model training. A simple way to start is by creating high-level categories to sort your data sources, giving you a clearer view of your data landscape.
For example, you could create categories such as:
- Owned data that you’re confident can be used
- Public data that needs to be assessed for usability
- Unowned data that should be kept out of AI initiatives
- Partially owned or licensed data that may have usage constraints or time limitations
This categorization simplifies the process of understanding your data and identifying potential risks or constraints. For instance, some data might be fine for internal testing but not for production use. Additionally, knowing where data is stored and centralizing it where possible can streamline access controls and documentation, ensuring a clear data lineage.
Once you’ve established some basic organizing principles, it’s easy to continue cataloging data as you create it or obtain it.
Tip 3: Balance governance with the need for experimentation
As we mentioned earlier, some data may be usable for internal development, but not suitable for production release. This is an important distinction to include in your catalog system. Allowing your team to be creative with internal data sources can lead to new ways of thinking about how your business can use AI. Placing too rigid of constraints on your data limits experimentation and innovation. As you build and implement data governance practices, keep in mind how your framework can impact your development team and aim to create a secure sandbox for fostering new ideas.
Tip 4: Be mindful of vendor and partner sprawl
Data and AI governance initiatives can also lead some organizations to bring in partners that clean, annotate, and organize data to support their AI initiatives. If you have a lot of valuable data you can’t use, your efforts could even involve hiring a company to recreate that data in a way that avoids legal or copyright issues.
While various types of partners can certainly help enable AI results, it’s important to remember that, in addition to adding costs, every third party you work with represents another data liability and potential security or governance problem. Data protection and data transparency demand keeping your AI supply chain as lean and trusted as possible.
Tip 5: Overcome data limitations with tools optimized for speed and security
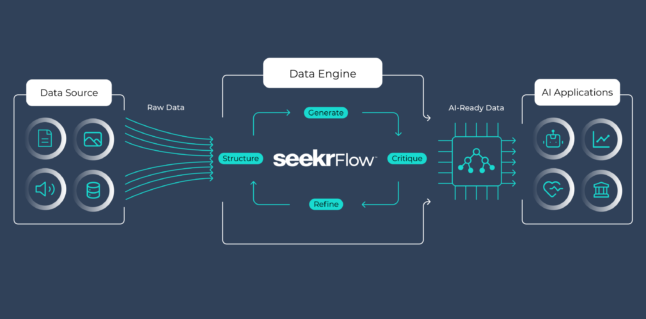
If you find that your production-viable data is limited, our SeekrFlow AI platform can help you navigate this challenge in an efficient way. The secret is our AI-Ready Data Engine, which converts diverse types of unstructured enterprise data into an AI-ready format based on the data you do have—with minimal user input. Simply provide a file containing the data you want to build upon, and our system generates a robust high-quality dataset rooted entirely in your proprietary information. This ensures your data is both safe and compliant for use, reducing risk for your organization.
For example, imagine a healthcare organization looking to train an AI model to predict patient outcomes. The organization’s sensitive patient data cannot be shared or used freely. With SeekrFlow, they can generate high-quality datasets based on anonymized internal records to implement successful AI solutions while maintaining compliance with data privacy regulations.
This agentic data creation process accelerates the value of your AI initiatives without introducing additional governance concerns. SeekrFlow allows you to explore AI opportunities quickly and confidently, knowing your data is both usable and secure.