SeekrFlow™ November Release: Build Trusted AI Workflows with Greater Control and Efficiency

Recently, we launched SeekrFlow™ as a complete platform for enterprises to train, validate, deploy, and scale trusted AI applications. Today, we’re introducing new features that offer users greater control and efficiency over their AI workflows—from optimizing model outputs to managing large-scale deployments.
For a full list of features, enhancements, and updated API documentation, visit the SeekrFlow release notes. Below, we’ll highlight the most impactful updates in our November 2024 release.
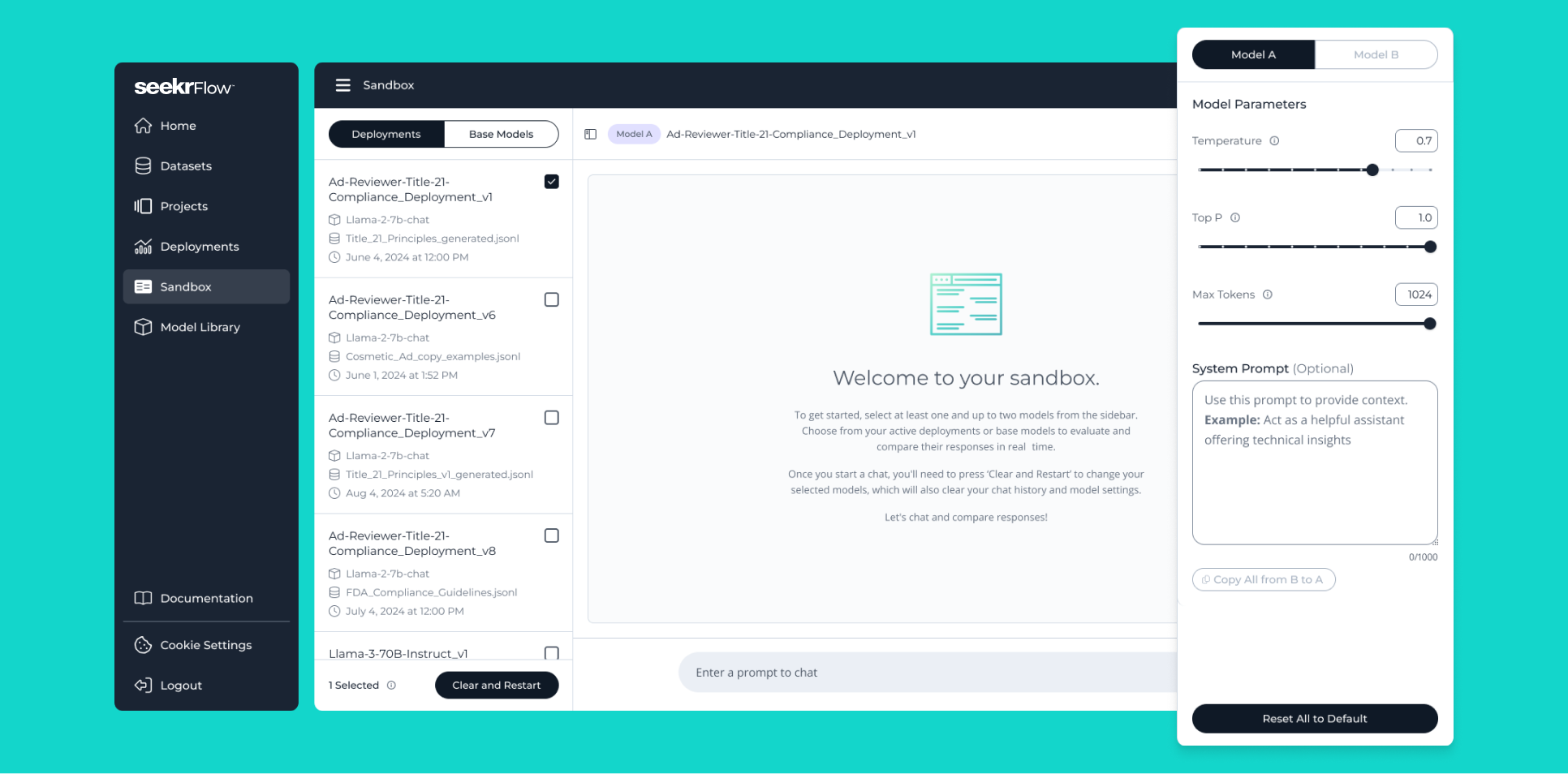
More control over your models at inference
Seekr’s Sandbox tool enables developers to explain, contest, and optimize model outputs to deploy more reliable AI applications. To provide greater control, we’ve added three new input parameters: Temperature, Top P, and Max Tokens.
Temperature
Adjusts the randomness or creativity of responses
- Higher temperature: Encourages diverse and imaginative responses, making it ideal for creative writing, brainstorming, or generating unique ideas.
- Lower temperature: Ensures precise and predictable results, essential for customer service chatbots, factual question-answering, and instructional content.
Top P
Expands the maximum set up of potential choices when generating a response
- Higher Top P: Allows for coherent yet varied dialogue, suitable for conversational AI in social interactions, like chatbots designed for engaging yet contextually appropriate replies.
- Lower Top P: helps reduce the risk of generating inappropriate or off-topic content, making it valuable for AI assistants in education or other sensitive applications.
Max Tokens
Defines response length to keep outputs concise or elaborate as required
- Lower Max Token: Useful for mobile applications or interfaces with limited screen space, ensuring responses are clear and to the point.
- Higher Max Token: Allow for comprehensive explanations, perfect for academic writing assistants or detailed content creation tools.
These parameters enable enterprises’ AI systems to adapt to specific requirements across industries—from ensuring accuracy in customer-facing chatbots to enabling creativity in content generation tools. Users now have the precision needed to meet diverse objectives. By leveraging these controls, enterprises can fine-tune their models for use cases that demand both versatility and reliability.
Transform your AI workflows with lightning-fast inference
Efficiency is critical in enterprise AI workflows. Our integration of an enhanced inference engine delivers faster response times and improved overall performance.
During performance benchmarks on Intel Gaudi 2 accelerators, the enhanced inference engine demonstrated the following:
- On average, 32% faster results compared to TGI in RAG experiments using Meta-Llama-3.1-8B-Instruct.
- Significant latency improvements in load testing with 100 concurrent users:
- Meta-Llama-3-8B-Instruct: 45% faster.
- Meta-Llama-3.1-8B-Instruct: 39% faster.
This level of optimization translates to tangible time savings for enterprises handling complex AI workloads. Faster processing enables teams to iterate and deploy solutions more quickly without sacrificing reliability or quality. For industries where seconds matter, this integration ensures every moment is used effectively.
Enhanced OpenAI compatibility features
To further streamline workflows, our inference engine offers compatibility with OpenAI’s ecosystem.
Log Probabilities (log_probs and top_logprobs) provide insights into the model’s decision-making process by quantifying the confidence of its predictions. These values help developers:
- Debug and fine-tune models effectively.
- Gain a deeper understanding of token-level decision-making.
Example: Token log probabilities indicate how confidently a model predicts each token based on context and the model’s training, with higher values suggesting—but not guaranteeing—greater likelihood of accuracy and the absence of hallucinations, thereby aiding transparency in AI operations.
Our engine supports dynamic tool calling, enabling users to supply custom functions. The model intelligently identifies when and how to invoke these tools based on the context.
How it works: Users provide a function signature, and the model generates a tool call suggestion when appropriate. This allows users to implement specific business logic seamlessly.
Create the client and make an API request
import os
import openai
# Set the API key
os.environ["OPENAI_API_KEY"] = "Paste your API key here"
# Create the OpenAI client and retrieve the API key.
client = openai.OpenAI(
base_url="https://flow.seekr.com/v1/inference",
api_key=os.environ.get("OPENAI_API_KEY"
)
# Send a request to the OpenAI API to leverage the specified Llama model as a unit conversion tool.
response = client.chat.completions.create(
model="meta-llama/Llama-3.1-8B-Instruct",
stream=False,
messages=[{
"role": "user",
"content": "Convert from 5 kilometers to miles"
}],
max_tokens=100,
tools=[{
"type": "function",
"function": {
"name": "convert_units",
"description": "Convert between different units of measurement",
"parameters": {
"type": "object",
"properties": {
"value": {"type": "number"},
"from_unit": {"type": "string"},
"to_unit": {"type": "string"}
},
"required": ["value", "from_unit", "to_unit"]
}
}
}]
)
Register a function from JSON
Next, define and register a Python function from JSON data.
# Parse json and register
def register_from_json(json_obj):
code = f"def {json_obj['name']}({', '.join(json_obj['args'])}):\n{json_obj['docstring']}\n{json_obj['code']}"
print(code)
namespace = {}
exec(code, namespace)
return namespace[json_obj["name"]]
Run the unit conversion tool
This function executes the tool call, given an LLM response object.
# Execute our tool
def execute_tool_call(resp):
tool_call = resp.choices[0].message.tool_calls[0]
func_name = tool_call.function.name
args = tool_call.function.arguments
func = globals().get(func_name)
if not func:
raise ValueError(f"Function {func_name} not found")
if isinstance(args, str):
import json
args = json.loads(args)
return func(**args)
execute_tool_call(response)
Sample output
This is the output expected in response to the request made earlier to convert 5 kilometers to miles.
3.106855
By combining speed, compatibility, and enhanced functionality, our inference engine empowers enterprises to scale AI applications while maintaining high performance and flexibility.
Eliminate wait times with chat response streaming
Waiting for lengthy model outputs can disrupt workflows. That’s why SeekrFlow now includes response streaming—a feature that allows users to see answers as they are generated, rather than waiting for the full reply to complete.
This feature enhances usability as:
- Users can see responses appear immediately, creating a smoother and more engaging experience. For customer support chatbots, for example, this can mimic real-time interactions, improving satisfaction and keeping users attentive.
- As responses are generated, users can begin processing the information sooner. If the response doesn’t meet their needs, they can rephrase or adjust their query without waiting for the full response to finish.
Response streaming enhances the user experience by reducing perceived wait times and enables more dynamic interactions with applications.
Seamless access for Intel® Tiber™ AI Cloud users
As part of our collaboration with Intel, we’ve introduced a seamless way for Intel® Tiber™ AI Cloud users to access SeekrFlow. Intel Cloud users can log in to SeekrFlow using their existing credentials to start building trusted AI applications that can be deployed securely and cost-effectively on Intel AI-optimized hardware. SeekrFlow on Intel® Tiber™ AI Cloud offers a 50% price advantage on model inference, compared to peers.
Get started with SeekrFlow today
With these updates, SeekrFlow continues to remove barriers to scalable and trusted AI development for the enterprise. That’s why our platform was recently recognized alongside AI industry leaders in GAI Insights’ Q4 2024 Corporate Buyers’ Guide to Enterprise Intelligence Applications.
Ready to transform your AI development process? Sign up for SeekrFlow today or book a consultation with a product expert to get started.


